Asymptotic Measures
From
m (→Big-Oh) |
|||
| (34 intermediate revisions not shown) | |||
| Line 1: | Line 1: | ||
| - | If we are going to compare the trade-off between Time and Space, we need a system of | + | <noinclude> |
| - | measurement. We certainly have units by which we measure particular instances of time and | + | {{CS2:BookNav|base=/|up=Contents: CS2|prev=Computability and Complexity|next=Empirical Measures}} |
| - | space, for example, seconds and bytes. However, when we compare the time or space usage | + | </noinclude> |
| - | of data structures and algorithms, we are more interested in how the usage changes as the | + | <br/> |
| - | size of the problem changes. That is, what is the scalability of a data structure or an | + | If we are going to compare the trade-off between Time and Space, we need a system of measurement. We certainly have units by which we measure particular instances of time and space, for example, seconds and bytes. However, when we compare the time or space usage of data structures and algorithms, we are more interested in how the usage changes as the size of the problem changes. That is, what is the scalability of a data structure or an algorithm? |
| - | algorithm? | + | |
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
| - | + | Therefore, we often classify the time or space usage of a data structure or an algorithm using asymptotic measures. There are six standard measures used, but we will only consider three of them. They are quite general in nature; that is, they provide bounds on the usage, and the definitions are mathematical definitions. Since a calculus background is necessary to understand the actual definitions, we will not look at the actual definitions; rather, we will just try to consider the implications of these measures. | |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | <br> | |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | == Big-Oh == | |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | The first measure we look at, and the most commonly used, is “Big-Oh” or O( N ). This measure provided an upper bound. That is, if the time or space usage were a cost that had to be paid by money, an upper bound says that the cost will be no more than this. The cost might be less, but not more. | |
| - | + | <br/><br/> | |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | The parameter N in this notation is some measure of the size of the problem. This might be the number of objects in a list that needs to be sorted, or it might be the number of bits needed to represent a number. These measures are called asymptotic—related to the mathematical concept of a limit line—because we are interested in large values of N. This means that the time or space needed to sort a list of 5 objects is not really of interest. But, the time or space needed to sort 100,000 objects or 100,000,000 is of interest. Further, we are not interested in the evaluation of a particular value of N; rather, we want to know how O( N ) changes as the value of N grows very large. | |
| - | The | + | <br/><br/> |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | Because we are interested in the relationship between N and O( N ) as N grows, the relationship is normally expressed as a function of N: O( f( N ) ). Typical functions used are the following: | |
| - | + | <br/><br/> | |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| + | *O( 1 ) [constant] | ||
| + | *O( log N ) [logarithmic] | ||
| + | *O( N ) [linear] | ||
| + | *O( N log N) [linearithmic] | ||
| + | *O( N<sup>2</sup> ) [quadratic] | ||
| + | *O( N<sup>c</sup> ) [polynomial] (where c >= 1) | ||
| + | *O( e<sup>N</sup> ) [exponential] | ||
| + | <br/> | ||
| - | [[ | + | Constant means that the time or space usage does not change as the size of the problem grows. Linear means that the time or space usage is directly proportional to the problem size. That is, if the size of the problem doubles, the time or space usage also doubles. In addition to quadratic, a polynomial relationship is any relationship where the base is N and the exponent is a number: N<sup>3</sup>, N<sup>4</sup>, etc. As a basic guide, any time or space usage that is polynomial or less is considered practical, while any usage that is exponential is considered not usable. For example, the Towers of Hanoi puzzle is exponential: it takes 2<sup>N -1</sup> moves to solve the puzzle for N rings. Suppose you could move 1 ring a second. You could solve a three ring puzzle in 7 seconds or a 4 ring puzzle in 15 seconds. How long would it take you to solve a 64 ring puzzle? ''It would take you over one-half a trillion years!'' |
| + | <br/><br/> | ||
| + | |||
| + | In addition, it is very important to remember that these asymptotic measures represent rates of growth, not particular values. For example, suppose I have two measures of time, T<sub>1</sub> and T<sub>2</sub>, where T<sub>1</sub> is logarithmic [T<sub>1</sub>( N ) = O( log<sub>2</sub> N )] and T<sub>2</sub> is quadratic [T<sub>2</sub>( N ) = O( N<sup>2</sup> )]. Note that T<sub>2</sub> grows at a faster rate than T<sub>1</sub>: for N = 2, 4, 8, and 16, T<sub>1</sub>( N ) = 1, 2, 3, and 4 but T<sub>2</sub>( N ) = 4, 16, 64, and 256. For some particular value of N or perhaps for many small values of N, T<sub>2</sub>( N ) may actually be a smaller value. This is because we drop coefficients in the mathematical expressions for asymptotic measures. | ||
| + | <br/><br/> | ||
| + | Here is a more detailed table from Wikipedia: | ||
| + | |||
| + | Here is a list of classes of functions that are commonly encountered when analyzing the running time of an algorithm. In each case, ''c'' is a constant and ''n'' increases without bound. The slower-growing functions are generally listed first. | ||
| + | |||
| + | {| class="wikitable" | ||
| + | !Notation !! Name !! Example | ||
| + | |- | ||
| + | |<math>O(1)\,</math> || [[Constant time|constant]] || Determining if a number is even or odd; using a constant-size [[lookup table]] or [[hash table]] | ||
| + | |- | ||
| + | |<math>O(\log n)\,</math> || [[Logarithmic time|logarithmic]] || Finding an item in a sorted array with a [[Binary search algorithm|binary search]] or a balanced search [[Tree_data_structure|tree]] | ||
| + | |- | ||
| + | |<math>O(n^c),\;0<c<1</math> || fractional power || Searching in a [[kd-tree]] | ||
| + | |- | ||
| + | |<math>O(n)\,</math> || [[linear time|linear]] || Finding an item in an unsorted list or a malformed tree (worst case); adding two ''n''-digit numbers | ||
| + | |- | ||
| + | |<math>O(n\log n)=O(\log n!)\,</math> || [[Linearithmic time|linearithmic]], loglinear, or quasilinear || Performing a [[Fast Fourier transform]]; [[heapsort]], [[quicksort]] (best and average case), or [[merge sort]] | ||
| + | |- | ||
| + | |<math>O(n^2)\,</math> || [[quadratic time|quadratic]] || Multiplying two ''n''-digit numbers by a simple algorithm; [[bubble sort]] (worst case or naive implementation), [[shell sort]], quicksort (worst case), [[selection sort]] or [[insertion sort]] | ||
| + | |- | ||
| + | |<math>O(n^c),\;c>1</math> || [[polynomial time|polynomial]] or algebraic || [[Tree-adjoining grammar]] parsing; maximum [[Matching (graph theory)|matching]] for [[bipartite graph]]s | ||
| + | |- | ||
| + | |<math>L_n[\alpha,c],\;0 < \alpha < 1=\,</math><br><math>e^{(c+o(1)) (\ln n)^\alpha (\ln \ln n)^{1-\alpha}}</math> || [[L-notation]] or [[sub-exponential time|sub-exponential]] || Factoring a number using the [[quadratic sieve]] or [[number field sieve]] | ||
| + | |- | ||
| + | |<math>O(c^n),\;c>1</math> || [[exponential time|exponential]] || Finding the (exact) solution to the [[traveling salesman problem]] using [[dynamic programming]]; determining if two logical statements are equivalent using [[brute-force search]] | ||
| + | |- | ||
| + | |<math>O(n!)\,</math> || [[factorial]] || Solving the traveling salesman problem via brute-force search; finding the [[determinant]] with [[expansion by minors]]. | ||
| + | |} | ||
| + | |||
| + | |||
| + | <br/><br/> | ||
| + | |||
| + | == Big-Omega == | ||
| + | |||
| + | The second asymptotic measure that we will look at is Big-Omega ( Ω( N ) ) . Big- Omega is similar to Big-Oh, except it is used to represent a lower bound. That is, it is a statement that a particular time or space usage will always be at least a certain amount. It may be more, but it will not be less. Another basic difference between Big-Oh and Big- Omega is that Big-Oh represents the upper bound of a particular data structure or algorithm; whereas, Big-Omega represents the lower bound for any data structure or algorithm that solves the particular problem, even a data structure or an algorithm that might not be invented yet. As you might expect, proving a lower bound is much more difficult than proving an upper bound. | ||
| + | |||
| + | <br> | ||
| + | |||
| + | == Big-Theta == | ||
| + | |||
| + | The third asymptotic measure to be considered is Big-Theta ( Θ( N ) ). A problem with Big-Oh and Big-Omega is the following. Suppose I am in the market for a brand new Ford Explorer. Well, I can check at car dealerships all around the state for prices. Is it true to say that an upper bound on a new Explorer is $1,000,000? That it may cost me less, but it is not going to cost me more than $1,000,000? Is it also true to say that a lower bound on a new Explorer is $0.01? Than it may cost me more, but it will not cost me less than $0.01? Both of the figures above are valid upper and lower bounds; however, they are ''not very useful'' upper and lower bounds. When the same expression can be used for both an upper and a lower bound, for example if the time usage of an algorithm is both O( N ) and Ω( N ), then we say it is Θ( N ). This means that Big-Theta represents a ''tight'' bound, one that is close to the actual value and is reasonable to use. However, at some point, T<sub>2</sub>( N ) will always be larger than T<sub>1</sub>( N ). | ||
| + | <br/><br/> | ||
| + | |||
| + | == Analysis of Algorithms == | ||
| + | The main concern here is to analyze approximately how long it takes various computer algorithms to run. We especially compare the running times of different algorithms for solving the same problem when the input data is in some sense large. In such cases the difference in running time between a fast algorithm and a slow one can be quite significant. We also sometimes analyze the amount of main memory space needed by various algorithms. Since memory is fairly cheap, this is usually not a big concern unless the amount of memory needed by an algorithm is very large. | ||
| + | <br/><br/> | ||
| + | |||
| + | As a simple example, consider the following section of code. Suppose that we want to estimate its running time. Suppose further that the compute function does something that is simple and that takes about the same amount of time each time it is called. Since there is not much else in this code but repeated calls to this compute function, a good estimate of the amount of running time can be made by adding up how many times compute gets called. What do you think we get? | ||
| + | <br/><br/> | ||
| + | |||
| + | <pre> | ||
| + | FOR k FROM 0 TO n - 1 BY 1 | ||
| + | FOR j FROM 0 TO n - 1 BY 1 | ||
| + | compute(k, j) | ||
| + | ENDFOR | ||
| + | compute(k, n) | ||
| + | ENDFOR | ||
| + | </pre> | ||
| + | |||
| + | Note that the number of calls of compute depends on the variable n. It is very common for the running time to be a function of a variable or variables like n. Since the outer loop executes its loop body n times and the inner loop as well, the compute(k, j) is called n^2 times. (Note that n^2 is being used to indicate n to the second power.) Since the compute(k, n) is outside of the inner loop, it is simply executed n times. The total number of calls of our compute function is thus n^2 + n. If one such function call takes about A seconds, the total running time is about A(n^2 + n) seconds. We write this running time function as t(n) = A(n^2 + n). As explained below, this particular function is an O(n^2) function. | ||
| + | <br/><br/> | ||
| + | |||
| + | '''Definition:''' A running time function t(n) is O(f(n)) provided that there is a'' constant c such that t(n) <= c * f(n) for all n beyond some number K''. (In other words, t is eventually bounded by a multiple of f.) | ||
| + | <br/><br/> | ||
| + | |||
| + | We usually read the statement that "t(n) is O(f(n))" as "t(n) is '''big-O''' of f(n)". The definition can best be understood by looking at a graph: | ||
| + | |||
| + | [[Image:Analysis1.gif]] | ||
| + | |||
| + | Note that this only tells you what happens eventually; it says nothing about how t and f compare initially. The O() notation looks at behavior for large n (where running times are very important). The following definition says something even more exact about the growth of a running time function: | ||
| + | <br/><br/> | ||
| + | |||
| + | '''Definition:''' A running time function t(n) is '''Θ(f(n))''' provided that there are constants c and d such that c * f(n) <= t(n) <= d * f(n) for all n beyond some number K. (In other words, t is eventually bounded above and below by multiples of f.) | ||
| + | <br/><br/> | ||
| + | |||
| + | Θ is the Greek letter capital Theta. We read the statement that "t(n) is Θ(f(n))" as "t(n) is''' big-Theta''' of f(n)". We also sometimes say that "t(n) has '''order''' f(n)" or that "t(n) has the same '''order of magnitude''' as f(n)". In a picture we have something like the following: | ||
| + | |||
| + | [[Image:Analysis2.gif]] | ||
| + | |||
| + | '''Theorem:''' Any polynomial with leading term c * n^k is O(n^k). In fact, it is Θ(n^k). | ||
| + | <br/><br/> | ||
| + | |||
| + | We won't prove this, but will just look at examples of its use: | ||
| + | <br/><br/> | ||
| + | |||
| + | '''Examples:''' | ||
| + | |||
| + | f(n) = 2*n^2 + n - 3 is Θ(n^2) | ||
| + | |||
| + | g(n) = 5*n^3 + n^2 - 3*n + 14 is Θ(n^3) | ||
| + | <br/><br/> | ||
| + | |||
| + | Roughly speaking, a Theta(n^2) function grows like the n^2 function, at least for large values of n. For example, if you triple n, you would expect the function value to be about 3^2 = 9 times as much. A Theta(n^3) function grows roughly like the n^3 function, at least for large n. Thus, if you triple n, you would expect the function value to be about 3^3 = 27 times as large. You might want to try graphing a Theta(n^3) function versus a Theta(n^2) one. Beyond a certain point the n^3 one takes much more time. As n increases, the difference gets progressively worse. | ||
| + | <br/><br/> | ||
| + | |||
| + | Exponential functions (such as t(n) = 2^n) are incredibly bad for running time functions. They are known to have a worse order of magnitude than any polynomial function. An algorithm with exponential running time may take centuries to complete even for only moderately large values of n. | ||
| + | |||
| + | The following chart gives a comparison of some common orders of magnitude for running time functions. Note that lg(n) is used to mean log base 2 of n. | ||
| + | <br/> | ||
| + | |||
| + | <pre> | ||
| + | BEST || WORST | ||
| + | ----------------------------------------------------------------- | ||
| + | lg(n) n n*lg(n) n^2 n^3 n^4 etc... || 2^n n! | ||
| + | fairly good || hopeless | ||
| + | || | ||
| + | </pre> | ||
| + | |||
| + | As a general rule, '''polynomial''' running times are generally all reasonable to do on real computers, but '''exponential''' running times are totally impractical except for very small values on n. | ||
| + | <br/><br/> | ||
| + | ---- | ||
| + | {{CS2/ChapNav}} | ||
| + | ---- | ||
| + | [[Category:CS0|{{SUBPAGENAME}}]] | ||
| + | [[Category:CS2|{{SUBPAGENAME}}]] | ||
Current revision as of 05:24, 5 April 2010
| ← Computability and Complexity | ↑ Contents: CS2 | Empirical Measures → |
If we are going to compare the trade-off between Time and Space, we need a system of measurement. We certainly have units by which we measure particular instances of time and space, for example, seconds and bytes. However, when we compare the time or space usage of data structures and algorithms, we are more interested in how the usage changes as the size of the problem changes. That is, what is the scalability of a data structure or an algorithm?
Therefore, we often classify the time or space usage of a data structure or an algorithm using asymptotic measures. There are six standard measures used, but we will only consider three of them. They are quite general in nature; that is, they provide bounds on the usage, and the definitions are mathematical definitions. Since a calculus background is necessary to understand the actual definitions, we will not look at the actual definitions; rather, we will just try to consider the implications of these measures.
Contents |
Big-Oh
The first measure we look at, and the most commonly used, is “Big-Oh” or O( N ). This measure provided an upper bound. That is, if the time or space usage were a cost that had to be paid by money, an upper bound says that the cost will be no more than this. The cost might be less, but not more.
The parameter N in this notation is some measure of the size of the problem. This might be the number of objects in a list that needs to be sorted, or it might be the number of bits needed to represent a number. These measures are called asymptotic—related to the mathematical concept of a limit line—because we are interested in large values of N. This means that the time or space needed to sort a list of 5 objects is not really of interest. But, the time or space needed to sort 100,000 objects or 100,000,000 is of interest. Further, we are not interested in the evaluation of a particular value of N; rather, we want to know how O( N ) changes as the value of N grows very large.
Because we are interested in the relationship between N and O( N ) as N grows, the relationship is normally expressed as a function of N: O( f( N ) ). Typical functions used are the following:
- O( 1 ) [constant]
- O( log N ) [logarithmic]
- O( N ) [linear]
- O( N log N) [linearithmic]
- O( N2 ) [quadratic]
- O( Nc ) [polynomial] (where c >= 1)
- O( eN ) [exponential]
Constant means that the time or space usage does not change as the size of the problem grows. Linear means that the time or space usage is directly proportional to the problem size. That is, if the size of the problem doubles, the time or space usage also doubles. In addition to quadratic, a polynomial relationship is any relationship where the base is N and the exponent is a number: N3, N4, etc. As a basic guide, any time or space usage that is polynomial or less is considered practical, while any usage that is exponential is considered not usable. For example, the Towers of Hanoi puzzle is exponential: it takes 2N -1 moves to solve the puzzle for N rings. Suppose you could move 1 ring a second. You could solve a three ring puzzle in 7 seconds or a 4 ring puzzle in 15 seconds. How long would it take you to solve a 64 ring puzzle? It would take you over one-half a trillion years!
In addition, it is very important to remember that these asymptotic measures represent rates of growth, not particular values. For example, suppose I have two measures of time, T1 and T2, where T1 is logarithmic [T1( N ) = O( log2 N )] and T2 is quadratic [T2( N ) = O( N2 )]. Note that T2 grows at a faster rate than T1: for N = 2, 4, 8, and 16, T1( N ) = 1, 2, 3, and 4 but T2( N ) = 4, 16, 64, and 256. For some particular value of N or perhaps for many small values of N, T2( N ) may actually be a smaller value. This is because we drop coefficients in the mathematical expressions for asymptotic measures.
Here is a more detailed table from Wikipedia:
Here is a list of classes of functions that are commonly encountered when analyzing the running time of an algorithm. In each case, c is a constant and n increases without bound. The slower-growing functions are generally listed first.
| Notation | Name | Example |
|---|---|---|
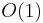 |
constant | Determining if a number is even or odd; using a constant-size lookup table or hash table |
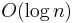 |
logarithmic | Finding an item in a sorted array with a binary search or a balanced search tree |
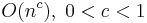 |
fractional power | Searching in a kd-tree |
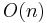 |
linear | Finding an item in an unsorted list or a malformed tree (worst case); adding two n-digit numbers |
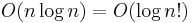 |
linearithmic, loglinear, or quasilinear | Performing a Fast Fourier transform; heapsort, quicksort (best and average case), or merge sort |
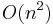 |
quadratic | Multiplying two n-digit numbers by a simple algorithm; bubble sort (worst case or naive implementation), shell sort, quicksort (worst case), selection sort or insertion sort |
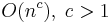 |
polynomial or algebraic | Tree-adjoining grammar parsing; maximum matching for bipartite graphs |
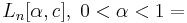 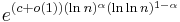 |
L-notation or sub-exponential | Factoring a number using the quadratic sieve or number field sieve |
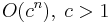 |
exponential | Finding the (exact) solution to the traveling salesman problem using dynamic programming; determining if two logical statements are equivalent using brute-force search |
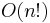 |
factorial | Solving the traveling salesman problem via brute-force search; finding the determinant with expansion by minors. |
Big-Omega
The second asymptotic measure that we will look at is Big-Omega ( Ω( N ) ) . Big- Omega is similar to Big-Oh, except it is used to represent a lower bound. That is, it is a statement that a particular time or space usage will always be at least a certain amount. It may be more, but it will not be less. Another basic difference between Big-Oh and Big- Omega is that Big-Oh represents the upper bound of a particular data structure or algorithm; whereas, Big-Omega represents the lower bound for any data structure or algorithm that solves the particular problem, even a data structure or an algorithm that might not be invented yet. As you might expect, proving a lower bound is much more difficult than proving an upper bound.
Big-Theta
The third asymptotic measure to be considered is Big-Theta ( Θ( N ) ). A problem with Big-Oh and Big-Omega is the following. Suppose I am in the market for a brand new Ford Explorer. Well, I can check at car dealerships all around the state for prices. Is it true to say that an upper bound on a new Explorer is $1,000,000? That it may cost me less, but it is not going to cost me more than $1,000,000? Is it also true to say that a lower bound on a new Explorer is $0.01? Than it may cost me more, but it will not cost me less than $0.01? Both of the figures above are valid upper and lower bounds; however, they are not very useful upper and lower bounds. When the same expression can be used for both an upper and a lower bound, for example if the time usage of an algorithm is both O( N ) and Ω( N ), then we say it is Θ( N ). This means that Big-Theta represents a tight bound, one that is close to the actual value and is reasonable to use. However, at some point, T2( N ) will always be larger than T1( N ).
Analysis of Algorithms
The main concern here is to analyze approximately how long it takes various computer algorithms to run. We especially compare the running times of different algorithms for solving the same problem when the input data is in some sense large. In such cases the difference in running time between a fast algorithm and a slow one can be quite significant. We also sometimes analyze the amount of main memory space needed by various algorithms. Since memory is fairly cheap, this is usually not a big concern unless the amount of memory needed by an algorithm is very large.
As a simple example, consider the following section of code. Suppose that we want to estimate its running time. Suppose further that the compute function does something that is simple and that takes about the same amount of time each time it is called. Since there is not much else in this code but repeated calls to this compute function, a good estimate of the amount of running time can be made by adding up how many times compute gets called. What do you think we get?
FOR k FROM 0 TO n - 1 BY 1
FOR j FROM 0 TO n - 1 BY 1
compute(k, j)
ENDFOR
compute(k, n)
ENDFOR
Note that the number of calls of compute depends on the variable n. It is very common for the running time to be a function of a variable or variables like n. Since the outer loop executes its loop body n times and the inner loop as well, the compute(k, j) is called n^2 times. (Note that n^2 is being used to indicate n to the second power.) Since the compute(k, n) is outside of the inner loop, it is simply executed n times. The total number of calls of our compute function is thus n^2 + n. If one such function call takes about A seconds, the total running time is about A(n^2 + n) seconds. We write this running time function as t(n) = A(n^2 + n). As explained below, this particular function is an O(n^2) function.
Definition: A running time function t(n) is O(f(n)) provided that there is a constant c such that t(n) <= c * f(n) for all n beyond some number K. (In other words, t is eventually bounded by a multiple of f.)
We usually read the statement that "t(n) is O(f(n))" as "t(n) is big-O of f(n)". The definition can best be understood by looking at a graph:

Note that this only tells you what happens eventually; it says nothing about how t and f compare initially. The O() notation looks at behavior for large n (where running times are very important). The following definition says something even more exact about the growth of a running time function:
Definition: A running time function t(n) is Θ(f(n)) provided that there are constants c and d such that c * f(n) <= t(n) <= d * f(n) for all n beyond some number K. (In other words, t is eventually bounded above and below by multiples of f.)
Θ is the Greek letter capital Theta. We read the statement that "t(n) is Θ(f(n))" as "t(n) is big-Theta of f(n)". We also sometimes say that "t(n) has order f(n)" or that "t(n) has the same order of magnitude as f(n)". In a picture we have something like the following:

Theorem: Any polynomial with leading term c * n^k is O(n^k). In fact, it is Θ(n^k).
We won't prove this, but will just look at examples of its use:
Examples:
f(n) = 2*n^2 + n - 3 is Θ(n^2)
g(n) = 5*n^3 + n^2 - 3*n + 14 is Θ(n^3)
Roughly speaking, a Theta(n^2) function grows like the n^2 function, at least for large values of n. For example, if you triple n, you would expect the function value to be about 3^2 = 9 times as much. A Theta(n^3) function grows roughly like the n^3 function, at least for large n. Thus, if you triple n, you would expect the function value to be about 3^3 = 27 times as large. You might want to try graphing a Theta(n^3) function versus a Theta(n^2) one. Beyond a certain point the n^3 one takes much more time. As n increases, the difference gets progressively worse.
Exponential functions (such as t(n) = 2^n) are incredibly bad for running time functions. They are known to have a worse order of magnitude than any polynomial function. An algorithm with exponential running time may take centuries to complete even for only moderately large values of n.
The following chart gives a comparison of some common orders of magnitude for running time functions. Note that lg(n) is used to mean log base 2 of n.
BEST || WORST
-----------------------------------------------------------------
lg(n) n n*lg(n) n^2 n^3 n^4 etc... || 2^n n!
fairly good || hopeless
||
As a general rule, polynomial running times are generally all reasonable to do on real computers, but exponential running times are totally impractical except for very small values on n.
CS2: Data Structures
Theory of Computation - ADT Preliminaries
Linear ADTs - Tree ADTs - Graph ADTs - Unordered Collection ADTs
