Binary Trees
From
| Begin | ↑ Tree ADTs | Multi-Way Trees → |

A binary tree is is a tree ADT that is restricted to having at most 2 children in each node contained in the tree. As computers generally operated on digital/binary logic, binary trees are very natural and efficient structures. They are useful both as a means of storing and organizing data, and as a means of representing a solution to a problem.
Contents |
Implementation of binary trees
A binary tree can be implemented in two basic ways. One way is a pointer based implementation—using dynamic memory—and the other way is an array based implementation—using static memory.
In a pointer based implementation, a tree node normally consists of three fields. They are usually called Data, Left, and Right. The Data field holds what ever information is to be represented by the tree, while the Left and Right fields are pointers to tree nodes. The links are normally one way: we can go from a parent to a child but not the other way.
In an array based implementation, the root of the tree is stored in position 0. For any node in position r, the left child is found in position 2r + 1 and the right child is found in position 2r + 2. One advantage of an array based implementation is that it is easy to go from a child to a parent: if the child is in location r and r > 0, then (r-1)/2, if r is odd, gives the location of the parent, and (r-2)/2, if r is even, gives the location of the parent. Also, if r > 0 and r is even, then r – 1 is the location of the sibling. And if r > 0 and r is odd, r + 1 is the location of the sibling.
Traversing a Binary Tree
Traversing a tree means to move systematically from node to node until all nodes have been covered or visited. There are several different algorithms for traversing a binary tree. In these algorithms we use a generic term called visit to indicate the operation that is being performed at each node. We also assume that we have a means of marking a node once it is visited. We may think of this as leaving a trail of bread crumbs or painting the node blue or leaving a post-it note that we were here.
The algorithms fall into two basic styles: breadth-first or depth-first traversals. The depthfirst traversals are called in-order, pre-order, post-order. What distinguishes a breadthfirst traversal from a depth-first traversal is the data structure that is used to hold the nodes we are waiting to visit. A breadth-first traversal uses a queue to hold the nodes and a depthfirst traversal uses a stack to hold the nodes we are waiting to visit.
We will consider the depth-first traversals first.
Depth-first traversals are almost always expressed in a recursive algorithm because it is very easy to describe the algorithm.
In-Order Traversal( Node N )
IF N is not NULL
In-Order Traversal( N.left )
Visit( N )
In-Order Traversal( N.right )
ENDIF
In-Order Traversal of the example tree above: 2, 7, 5, 6, 11, 2, 5, 4, 9
Pre-Order Traversal( Node N )
IF N is not NULL
Visit( N )
Pre-Order Traversal( N.left )
Pre-Order Traversal( N.right )
ENDIF
Pre-Order Traversal of the example tree above: 2, 7, 2, 6, 5, 11, 5, 9, 4
Post-Order Traversal( Node N )
IF N is not NULL
Post-Order Traversal( N.left )
Post-Order Traversal( N.right )
Visit( N )
ENDIF
Post-Order Traversal of the example tree above: 2, 5, 11, 6, 7, 4, 9, 5, 2
A Breadth-First Traversal has the following algorithm
Let Q be a queue that holds tree nodes and let P be a pointer to tree nodes.
Enqueue the root of the tree.
WHILE the queue is not empty do the following
Dequeue a node and assign it to P
Visit the node pointed to by P
IF the node pointed to by P has a left child
enqueue the left child
ENDIF
IF the node pointed to by P has a right child
enqueue the right child
ENDIF
ENDWHILE
Using this algorithm we get: 2, 7, 5, 2, 6, 9, 5, 11, 4. A breadth-first traversal is often called a level-order traversal.
Types of binary trees
- A rooted binary tree is a rooted tree in which every node has at most two children.
- A full binary tree (sometimes proper binary tree or 2-tree) is a tree in which every node other than the leaves has two children.
- A perfect binary tree is a full binary tree in which all leaves are at the same depth or same level. (This is ambiguously also called a complete binary tree.)
- A complete binary tree is a binary tree in which every level, except possibly the last, is completely filled, and all nodes are as far left as possible.
- An infinite complete binary tree is a tree with
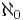 levels, where for each level d the number of existing nodes at level d is equal to 2d. The cardinal number of the set of all nodes is . The cardinal number of the set of all paths is
levels, where for each level d the number of existing nodes at level d is equal to 2d. The cardinal number of the set of all nodes is . The cardinal number of the set of all paths is 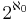 .
. - A balanced binary tree is where the depth of all the leaves differs by at most 1. Balanced trees have a predictable depth (how many nodes are traversed from the root to a leaf, root counting as node 0 and subsequent as 1, 2, ..., depth). This depth is equal to the integer part of log2(n) where n is the number of nodes on the balanced tree. Example 1: balanced tree with 1 node, log2(1) = 0 (depth = 0). Example 2: balanced tree with 3 nodes, log2(3) = 1.59 (depth=1). Example 3: balanced tree with 5 nodes, log2(5) = 2.32 (depth of tree is 2 nodes).
- A rooted complete binary tree can be identified with a free magma.
- An almost complete binary tree is a tree in which each node that has a right child also has a left child. Having a left child does not require a node to have a right child. Stated alternately, an almost complete binary tree is a tree where for a right child, there is always a left child, but for a left child there may not be a right child.
- A degenerate tree is a tree where for each parent node, there is only one associated child node. This means that in a performance measurement, the tree will behave like a linked list data structure.
- The number of nodes n in a perfect binary tree can be found using this formula: n = 2h + 1 − 1 where h is the height of the tree.
- The number of nodes n in a complete binary tree is minimum: n = 2h and maximum: n = 2h + 1 − 1 where h is the height of the tree.
- The number of nodes n in a perfect binary tree can also be found using this formula: n = 2L − 1 where L is the number of leaf nodes in the tree.
- The number of leaf nodes n in a perfect binary tree can be found using this formula: n = 2h where h is the height of the tree.
- The number of NULL links in a Complete Binary Tree of n-node is (n+1).
- The number of leaf node in a Complete Binary Tree of n-node is UpperBound(n / 2).
- Note that this terminology often varies in the literature, especially with respect to the meaning "complete" and "full".
Example Binary Search Tree Applications
Expression Tree
An expression tree is a way of representing expressions involving binary operators. A node in an expression tree either has two children or no children. Internal nodes hold operators and the left and right subtrees contain the left and right sides of the expression to be evaluated.
For example, consider the expression 2 * (3 + 4). Now consider traversals where the visit operation is to print out the data contained in the node.
...IMAGE HERE...
An in-order traversal gives: 2 * 3 + 4. This is called '''infix''' notation A pre-order traversal gives: * 2 + 3 4. This is called '''prefix''' notation A post-order traversal gives: 2 3 4 + *. This is called '''postfix''' notation.
Note that with postfix notation, a stack can be used to evaluate the expression. We process the string from left to right one symbol at a time. If the symbol is a number, push the number on the stack. If the symbol is an operator, pop the top 2 numbers, perform the operation with these numbers (The first number popped is the left operand; the second number popped is the right operand.), and push the result back on the stack. A correctly formed expression ends with one number left in the stack. This number is the value of the expression.
Huffman Encoding
Normally characters in text are represented by fixed groups of bits using an encoding sequence such as ASCII or Unicode. In order to allow for easy decoding, all symbols use the same number of bits: 8 bits in the case of ASCII. However, suppose I want to compress a file. One way to do this would be to use a variable number of bits where the letters that appear most frequently use a small number of bits and the letters that appear less often use a larger number of bits. Such is the idea behind Huffman encoding.
However, when using variable groups of bits, we must be careful that the pattern of bits that represents one letter is not also a prefix for another letter. For example, I decide to translate the Morse Code from dots and dashes to zeros (a dot) and ones (a dash). Consider, then the following letters. The letter ‘E’, which is represented by a dot in Morse Code; the letter ‘U’, which is represented by dot, dot, dash; and the letter ‘V’, which is represented by dot, dot, dot, dash. Now there is a binary sequence 0001. Does this represent the letters EU? or the letter V? This is an example of the prefix problem.
A Huffman code is a binary code that uses a variable number of bits for letters (or any other symbol). It is a frequency based code, which means that the symbols that occur the most frequently use fewer bits than the symbols that occur occasionally. The algorithm to create the code, uses a binary tree with two types of nodes. The internal nodes store a frequency and the leafs store a symbol. For example, suppose I had a text file that contained the following letters with the given frequency:
...TABLE TO GO HERE...
Based on this table, the algorithm would create a tree that looks like the following:
....IMAGE TO GO HERE...
Now if we label each edge to a left child with a 0 and each edge to a right child with a 1, the edge labels for the path from the root to each letter forms the code for that letter. For example, using the tree above, the letter E is encoded with 0 and the letter Z is encoded with 111100.
Given the string 111111011111010, what does it represent? We start from the root and following the left or right edges until we reach a leaf. We repeat this process until all the digits of the input string are used. Using the given string, we find:
...IMAGE TO GO HERE...
Notice that this 4 letter word takes 15 bits to represent, but the ASCII representation is 32 bits (8 bits per symbol). This is a 53% compression.
Binary Tree Implementations
CS2: Data Structures
Theory of Computation - ADT Preliminaries
Linear ADTs - Tree ADTs - Graph ADTs - Unordered Collection ADTs
